De verificatie van de structuur van de Mercator-database, in geavanceerde tools, probeert om een unieke index te installeren op de pieds-tabellen (PIEDS_V, PIEDS_A, PIEDS_C), waarvan de expressie JOURNAL,ID. Het doel hiervan is de uniciteit van de kolommen ID en JOURNAL te waarborgen. Inderdaad, deze combinatie is gebruikt om de link te leggen tussen de SQL-bestanden die verbonden zijn aan de documenten uit het commercieel beheer of de boekhouding.
Indien er niet voldaan kan worden aan deze uniciteit, zal het onmogelijk zijn om een unieke index toe te voegen. Hieronder de queries voor gegevens uit de tabel PIEDS_V. Ze kunnen eenvoudig aangepast worden voor de twee andere tabellen.
De unieke index die Mercator probeert te installeren is de volgende:
create unique index PIEDS_V_UNIQUE_ID_PER_JOURNAL on dbo.PIEDS_V (JOURNAL, ID)
De volgende querie laat ons toe om dubbels te tonen:
select id,journal,count(*) from PIEDS_V group by id,journal having count(*)>1
Om de patch hieronder toe te passen is het noodzakelijk om de Update rule op Cascade te plaatsen op de constraint van de vreemde sleutel tussen PIEDS_V en LIGNES_V (FK_LIGNES_V_PIEDS).
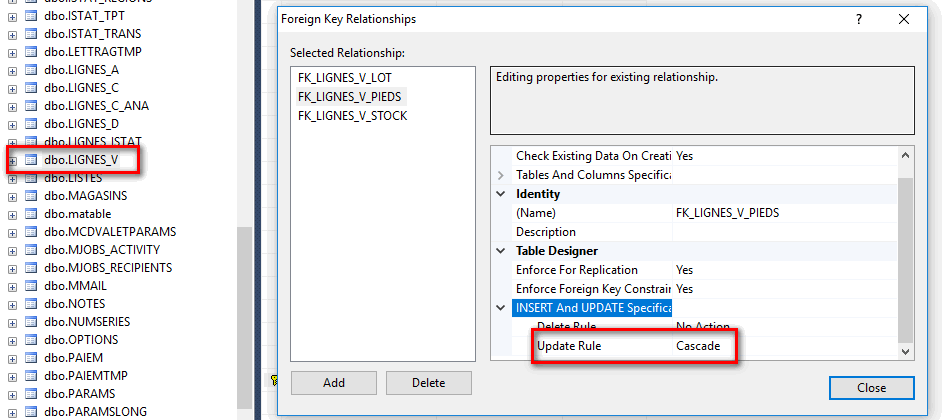
Indien dit nog niet actief is, kan je dit activeren door deze query uit te voeren:
alter table dbo.LIGNES_V drop constraint FK_LIGNES_V_PIEDS
GO
alter table dbo.LIGNES_V add constraint FK_LIGNES_V_PIEDS FOREIGN KEY (id,journal,piece) references pieds_v (id,journal,piece) on update cascade
alter table dbo.LIGNES_V CHECK CONSTRAINT FK_LIGNES_V_PIEDS
De volgende querie laat ons toe om duplicaten te corrigeren, het behoud het eerste document ID, en wijzigt de volgende:
select * into #pied_doublons_tmp from (
select id,journal,piece,ROW_NUMBER() OVER(PARTITION BY id,journal order by id,journal,piece) as n from PIEDS_V
) t where t.n>1
update PIEDS_V set id=right(newid(),10) from #pied_doublons_tmp p
where (pieds_v.id=p.id) and (pieds_v.journal=p.journal) and (pieds_v.piece=p.piece)
drop table #pied_doublons_tmp
We raden aan om deze correctie uit te voeren nadat je een back-up genomen hebt van de database.
We vestigen onze aandacht op het feit dat er bestanden gekoppeld kunnen zijn aan de duplicaten (bijvoorbeeld A, B en C) van documenten/boekingen:
- voor de correctie werden alle bijlagen in hetzelfde object "verkenner" afgebeeld. In documenten A, B en C zien we alle bijlagen die aan A, B en C gekoppeld zijn.
- na de correctie zijn de bijlagen enkel zichtbaar in A. Er zullen geen bijlagen meer zijn in documenten B en C.
Bijgevolg kan het nodig zijn om bestanden handmatig te herklasseren.
Sleutelwoorden: structuur verifiëren